快1000倍!内存压缩技术可提高AI推理效率
2025年4月,瑞典内存优化知识产权(IP)供应商ZeroPoint Technologies(以下简称ZeroPoint)宣布与Rebellions建立战略合作伙伴关系,共同开发用于AI推理的下一代内存优化AI加速器。该公司计划在 2026 年发布一款新产品,并声称“有望实现前所未有的代币/秒/瓦特性能水平”。
作为合作的一部分,两家公司将使用 ZeroPoint 的内存压缩、压缩和内存管理技术来增加基本模型推理工作流程的内存带宽和容量。 ZeroPoint 首席执行官 Klas Moreau 声称其基于硬件的内存优化引擎比现有的软件压缩方法快 1,000 倍。
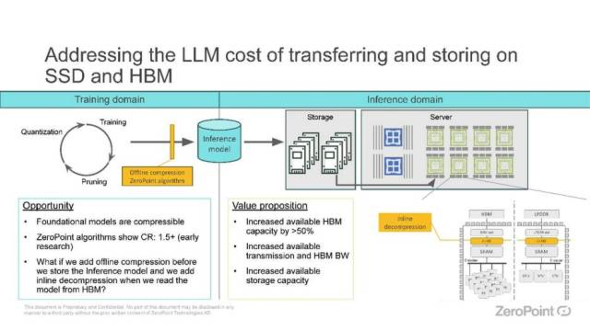
ZeroPoint 的内存压缩 IP 价值主张。来源:ZeroPoint
ZeroPoint 希望在不牺牲准确性的情况下提高代币/秒/瓦特,并使用无损模型压缩来减少模型尺寸和为模型组件供电所需的能量。
Rebellions 首席执行官 Sunghyun Park 在一份联合声明中表示:“在 Rebellions,我们对效率的关注正在推动尖端加速的界限。我们与 ZeroPoint 的合作将重新定义每瓦推理性能的可能性,并为生成式人工智能时代提供更智能、更高效、更可持续的人工智能基础设施。”
莫罗在一份声明中补充道:“我们相信内存加速将迅速从一种竞争优势发展成为所有高性能推理加速器解决方案的重要组成部分。我们很高兴分享 Rebellions 致力于为 AI 数据中心实现大规模效率的承诺。”
内存中存储了大量的“冗余数据”
今年早些时候,莫罗表示,内存中存储的数据超过 70% 都是冗余的。他表示:“这意味着你可以删除所有冗余数据,同时仍然提供无损压缩。但要实现无缝衔接,你需要一种能够在纳秒级窗口内(相当于几个系统时钟周期)完成三项非常具体操作的技术。”
首先,压缩和解压缩。其次,压缩生成的数据(将小块的压缩数据收集到单独的缓存行中,从而显著增加表观内存带宽)。第三,无缝管理数据,以跟踪内聚数据块的位置。为了最大限度地减少延迟,这类基于硬件的内存优化方法通常必须以缓存行粒度运行,这意味着它们必须以 64 字节的块为单位来压缩、压缩和管理数据(而现有的压缩技术(如 ZSTD 和 LZ4)则使用更大的 4-128kB 数据块),”Moreau 说道。
“如果做得正确,好处是巨大的:对于典型的工作负载,例如在超大规模数据中心,这可以导致可寻址内存容量/带宽增加 2-4 倍,每瓦性能提高 50%,并且总拥有成本 (TCO) 大幅降低(主要是由于效率提高),”他说。
莫罗说:“在开发这个解决方案的过程中,我们仔细研究了压缩、压缩和内存管理技术如何使基本模型工作负载受益。”
莫罗表示:“Marvell 和英特尔等公司在高带宽内存 (HBM) 方面取得的最新进展已经带来了性能提升,可以解决数据中心运营中长期存在的效率低下问题,但我们相信,引入硬件加速内存压缩、压缩和管理技术可以带来进一步的改进。”
“我们已经测试了这些假设,并发现对于大型语言模型(LLM)等专门的应用程序,软件压缩与内联硬件解压缩(增加最小的延迟)相结合已经将关键应用程序性能指标 - 可寻址内存,带宽和令牌/秒 - 提高了大约 50%,”他补充道。
未来,集成内联硬件压缩/解压缩技术将带来更大的性能提升。例如,数据中心中拥有 100 GB HBM 的基本模型工作负载,可以像拥有 150 GB HBM 一样运行,从而显著提高成本效益、性能和带宽。这可能带来数十亿美元的成本节省,并提升高性能 AI 模型的性能,”Moreau 说道。
莫罗补充道:“这些进步为 AI 芯片制造商提供了坚实的基础,以挑战 NVIDIA 等行业巨头的主导地位,并为他们提供了优化内存效率和性能的核心能力。” “这种授权将使他们不仅能够满足技术规格,还能通过在功率和成本效率方面的创新来参与全球竞争 - 这些因素对于广泛采用和技术独立至关重要。”
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序