如何预估部署大型语言模型需要多少的GPU vRAM?
在现如今人工智能迅速发展的时代,大型语言模型(Large Language Models, LLM)如GPT系列已成为各大科技公司和研究机构的核心工具。然而,这些模型通常拥有数十亿甚至上百亿的参数,对硬件资源,特别是GPU存储器(GPU vRAM)的需求极为庞大。本文将带您了解如何粗略估计如要部署一个70B (700亿)参数的LLM所需的GPU资源。
VRAM 是 RAM 的一个子集,通常用于描述DDR4 或 DDR5等内存。从技术上讲,这些类型的 RAM 适用于计算机中的所有组件,但它们实际上是针对 CPU 的性能要求量身定制的,CPU 希望快速传输数据,而不是一次传输大量数据。因此,DDR 内存一直专注于低延迟(低至纳秒),而不是带宽,带宽通常以 GB/秒为单位。
然而,GPU 不是 CPU,对内存的要求也大不相同。GPU 需要大量内存带宽才能访问纹理、帧缓冲区(告诉 GPU 在帧中将各个像素放置在何处)以及存储在 RAM 中的其他图形信息,并且可以容忍相对较高的延迟,这就是为什么 VRAM 不仅专门为适合图形处理器而设计,而且在物理上尽可能靠近 GPU。
首先将模型放到GPU vRAM时,每个参数在电脑中储存时会占用一定的位元组(Bytes),不同的精度格式对应不同的存储需求。以下是常见的参数存储格式及其占用的位元组数:
· Float32:每个参数占用4 位元组(Bytes)。
· Float16:每个参数占用2 位元组(Bytes)。
· Int8:每个参数占用1 位元组(Byte)。
· Int4:每个参数占用0.5 位元组(Bytes)。
如何计算模型参数的存储器需求?
了解上述的基本知识之后我们可以开始计算将一个Llama 3.1 70B 的模型搬到GPU vRAM 中会需要占用多少vRAM,Llama 3.1 70B是一个拥有700亿参数的LLM,以下是不同精度格式下所需的存储空间计算:
· 使用Float32
70,000,000,000 参数× 4 Bytes = 280,000,000,000 Bytes ≈ 260.9 GB
· 使用Float16
70,000,000,000 参数× 2 Bytes = 80,000,000,000 Bytes ≈ 130.5 GB
· 使用Int8
70,000,000,000 参数× 1 Byte = 40,000,000,000 Bytes ≈ 65.2 GB
· 使用Int4
70,000,000,000 参数× 0.5 Byte = 20,000,000,000 Bytes ≈ 32.6 GB
模型推论所需GPU vRAM
部署一个拥有700 亿(70B)参数的Llama3–70B 大型语言模型(LLM)进行推理时,GPU 存储器的使用量主要由以下几个部分组成:
· CUDA 核心占用的存储器(CUDA Kernal)。
· 模型参数占用的存储器(Model Parameter)。
· 中间变量占用的存储器(Intermediate Variables eg, Q, K, V, …)。
· 其他占用的存储器(eg, Buffers 和Outputs)。
CUDA 本身占用的存储器
每次使用GPU 时,CUDA 核心会占用一定量的VRAM。这部分的存储器消耗取决于GPU 型号、驱动程序和深度学习框架的版本。
约占用300 MB ~ 2 GB
模型参数占用的存储器
模型的存储器使用主要取决于参数的数量和它们的存储方式,不会受到其他因素引响(如Batch Size, Sequence Length)
假设Llama3–70B 模型使用4-bit 量化,这意味着每个参数仅占用4 bytes。因此,模型参数占用的存储器计算如下:
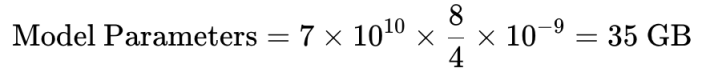
· 模型参数占大部分的GPU vRAM 用量,懒人计算法可以直接将这边算出来的vRAM 用量乘以1.2 当成推论时的用量。
· 增加20%用量包含CUDA Kernal, 中间变量, 模型输出等所消耗的存储器。
中间变量, 模型输出所消耗的存储器用量取决于Batch Size, Input Token Size…
中间变量占用的存储器
在推理过程中,模型会生成并存储一些临时的数据,比如Query、Key、Value 矩阵,这些数据也会占用部分GPU存储器。
影响中间变量占用的vRAM 因素主要有:Batch Size, Input Token Size。
Batch Size 与vRAM 用量成线性关系:

Input Token Size 与存储器用量成平方关系:

其他占用的存储器
除了模型参数和中间变量外,还有一些其他组件会占用vRAM,包括:
· Buffers:如预计算的位置信息编码(Positional Encodings)。
· Outputs:输出张量通常以float32 格式存储,即使模型本身使用较低精度。
· Optimizer States(仅在训练时):如Adam 或SGD 储存的梯度动量。
这项虽然会占用vRAM,在Inference 时主要关注的是模型参数和中间变量的存储器需求。
总体GPU vRAM 使用量公式
综合上述各部分,总的GPU RAM 使用量可以表示为:
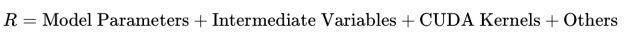
总结
在部署LLM 时,了解GPU 存储器的需求是非常关键的。模型的存储器使用主要受参数精度格式的影响,每种格式对应的存储器需求不同。
在推理过程中,除了模型参数外,还需考虑CUDA 核心、中间变量及其他相关的存储器需求。这些额外的需求通常占用模型参数存储器需求的约20%。尤其是Batch Size 和Input Token Size 会显著影响推理时的vRAM 使用量。因此,对于推理环境的优化,可以通过选择适合的参数格式及控制Batch Size 等因素来有效节省存储器资源。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序