详解Arrow Lake中的Lion Cove内存子系统
一个CPU核心在不同的部署平台上,其性能表现可能会大相径庭。这一点在Skymont核心于Lunar Lake和Arrow Lake平台上截然不同的性能特征中体现得淋漓尽致。我们已经介绍过英特尔在Lunar Lake平台上最新的P核架构——Lion Cove。现在,是时候看看它在Arrow Lake平台上的表现了,Arrow Lake是一个性能更高的平台。
Arrow Lake更高的功耗预算让酷睿Ultra 9 285K的性能核能够以5.7GHz的频率运行,而酷睿Ultra 7 258V中的性能核运行频率仅为4.8GHz 。更大的面积预算使Arrow Lake能为这些性能核配备36MB的三级缓存,相比之下,Lunar Lake只有12MB。缓存容量的提升也延伸到了核心层面,每个Arrow Lake性能核拥有3MB的二级缓存,相较于Lunar Lake的2.5MB稍有提升。最后,Arrow Lake还改善了DRAM的访问延迟。
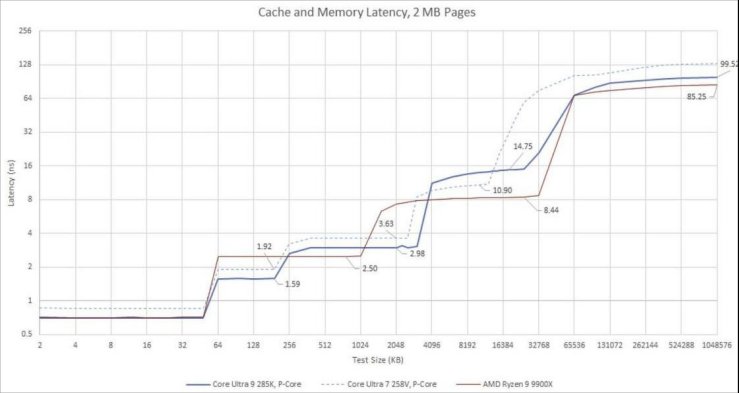
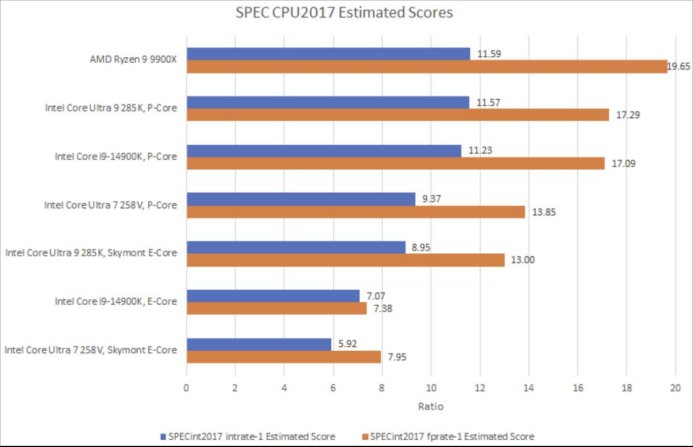
所有这些都意味着,与在Lunar Lake中相比,Lion Cove在Arrow Lake里速度更快,获得的资源也更充沛。在SPEC CPU2017测试中,这分别转化为整数测试套件24.8%的性能提升,以及浮点测试套件23.4%的性能提升。这一提升幅度超过了CPU代际之间的典型性能增幅。不过,它还没达到Skymont那种超50%的性能差异。这主要是因为Skymont在Lunar Lake中处于劣势,它没有三级缓存,而且二级缓存未命中延迟很高。Lunar Lake为其性能核提供资源时也算尽力了,实际上它的三级缓存延迟更低。Arrow Lake的内存子系统总体上更好,但它给Lion Cove带来的优势不像给Skymont带来的优势那么显著。
作个对比,AMD的Zen 5运行时的最高时钟频率与之几乎相同,但使用了更小的二级缓存和更快的三级缓存。这一代的AMD在DRAM访问速度上也更快。值得注意的是,这并非因为AMD推出了大幅改进的Zen 5内存控制器,而是相比上一代的Raptor Lake,Arrow Lake的DRAM延迟有所倒退。
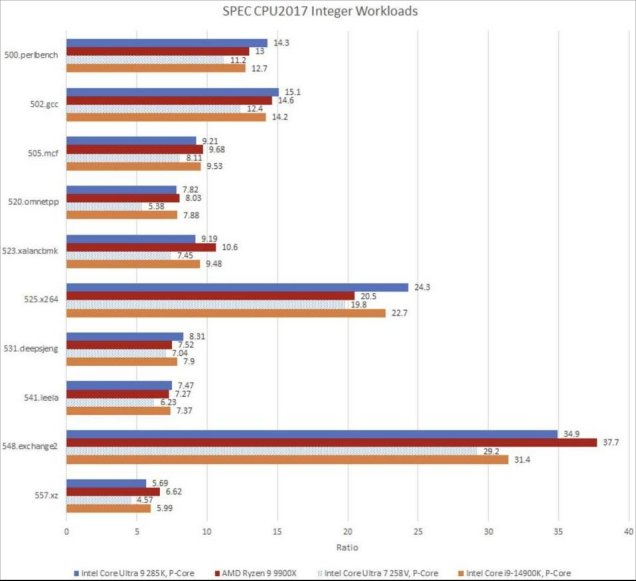
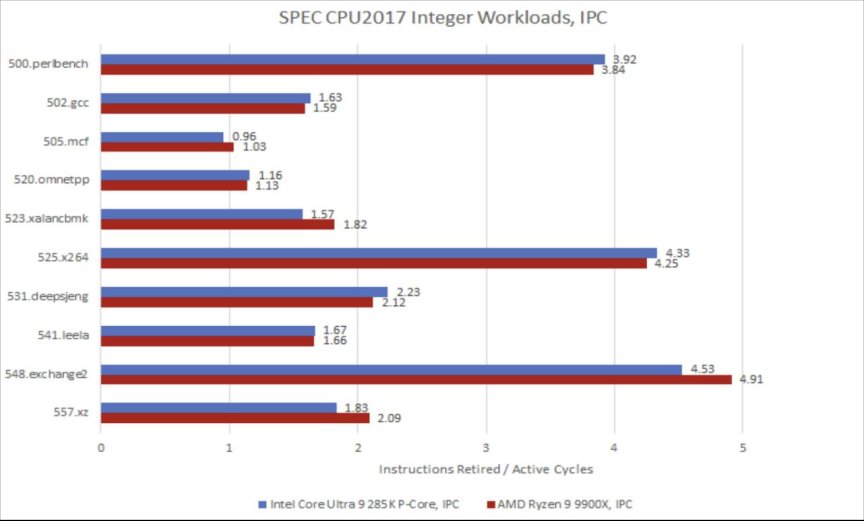
Raptor Lake也值得一谈,因为其Raptor Cove性能核与Arrow Lake的性能核表现非常接近。与前代相比,Lion Cove在SPEC整数测试套件中仅领先1.2%,在浮点测试套件中领先3% 。仔细查看各个工作负载会发现,在一些内存受限的测试,如505.mcf和520.omnetpp测试中,Raptor Lake的表现优于它的后继者。我怀疑Arrow Lake更高的DRAM延迟是造成这种情况的一个因素。在这些测试中,Zen 5领先于英特尔的这两种核心,这可能得益于更新的核心以及相当低的DRAM访问延迟。与此同时,面对更大的数据量时,Lunar Lake的Lion Cove核心表现极差。例如,在520.omnetpp测试中,Arrow Lake的Lion Cove核心比Lunar Lake中相同核心的速度快45%。
在另一个极端情况下,Lion Cove在高IPC(每时钟周期指令数)工作负载方面表现出色,这类工作负载的大部分工作集都可以存放在缓存中。Lion Cove并非是Skymont的完全复制品,但二者在部分性能特征上确有相似之处。它们都是8路超标量核心,只要能获得充足的数据供给,就能实现非常高的IPC。Zen 5也属于这类能在高IPC场景发挥优势的核心。
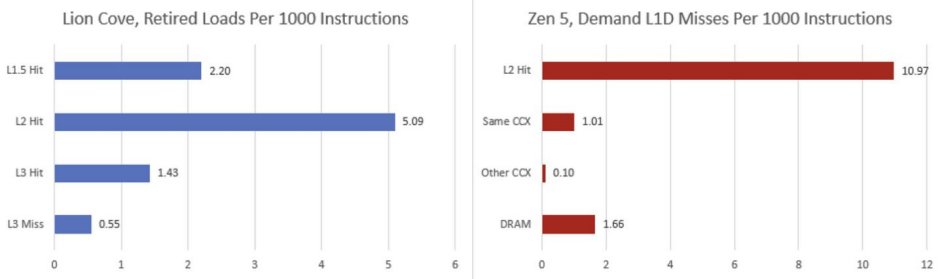
当情况变得棘手时,尽管Zen 5和Lion Cove采用了不同的缓存策略,但它们的表现仍然难分伯仲,当然,还是存在一些差异的。研究缓存命中率颇具挑战性,因为性能监测事件是针对每种架构特有的。英特尔和AMD在描述缓存未命中的方式上截然不同。英特尔在指令退役时报告加载指令的数据源,此时核心会进行最终检查,并使指令结果可见。AMD则会细分需求L1D未命中的数据源。“需求”意味着访问是由一条指令发起的,但这并不一定意味着该指令实际被执行(退役)了。例如,需求加载可能发生在分支预测错误之后。在这种情况下,加载指令永远不会退役,而且其数据很可能不会被使用。

令人倍感困惑的是,英特尔的性能监测文档竟将Lion Cove的192KB数据缓存称为“L1数据缓存的一级” 。想必英特尔的工程师们着实钟情于L1缓存命中(毕竟谁又会排斥呢),于是,他们在L1缓存内部又细分出了一个层级,以便在原本的L1缓存一级效果欠佳时,仍能达成这一“L1一级”的命中。实在难以想象,这一做法居然切实可行。为求表述简洁,后续我仍将其称作L1.5缓存。
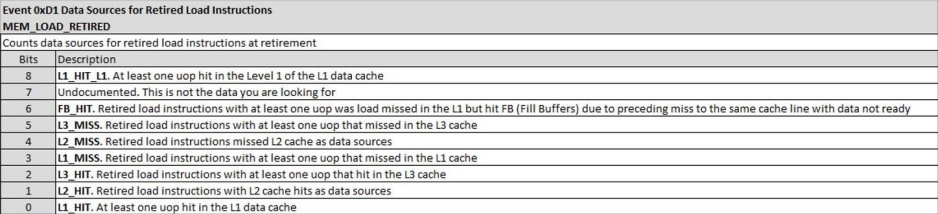
我获取了英特尔的JSON文档,并对其进行了格式编排,使其与AMD记录性能监测事件的方式相符。单元掩码的第8位,在事件选择寄存器里是从第40位起算的。英特尔针对这一内容的“文档”,基本上就是一条Linux内核提交记录。
尽管存在这些差异,性能监测事件确实为了解它们的缓存策略与不同工作负载的交互方式提供了线索。首先,英特尔的L1.5缓存的效果出奇地好。即便只有192KB,在某些工作负载下,它也足以捕获很大一部分L1D未命中的数据。在诸如525.x264这类特殊情况中,L1.5基本上取代了L2,成为L1D未命中时的主要数据源。
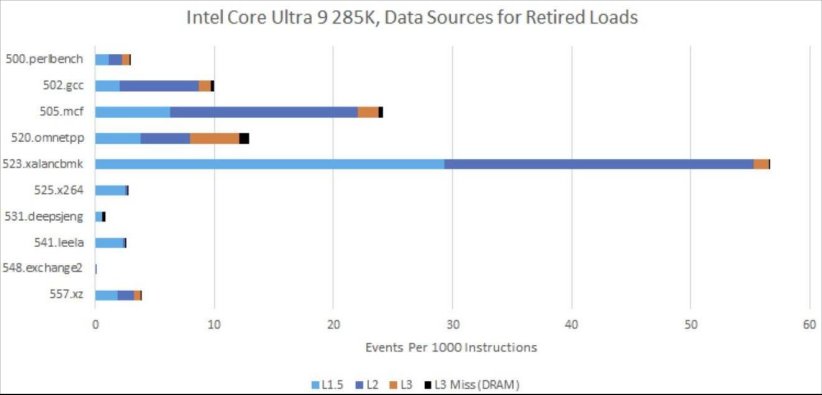
在相同的工作负载下,AMD必须依靠其延迟更高的L2缓存来处理所有这些L1D未命中的数据。这可能是导致在525.x264测试中,Lion Cove领先于Zen 5的原因之一。即便在内存访问行为较难预测的工作负载中,L1.5缓存也常常能减少流向L2缓存的数据量。
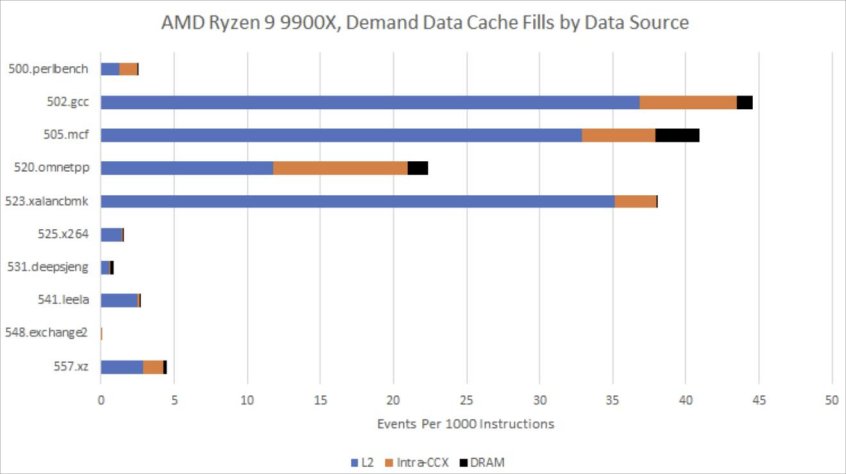
在这些测试中,Zen 5的表现也不尽如人意,但在两项测试中,它平均每时钟周期指令数(IPC)大约能达到1.45。我猜测Zen 5更低延迟的三级缓存以及DRAM访问起到了一定作用。

在SPEC CPU2017的浮点测试套件中,Lion Cove的L1.5缓存命中率参差不齐。在一些测试里,L1.5缓存几乎能够取代L2缓存,这常常让英特尔占据领先地位。而在其他测试中,L1.5缓存无法捕获足够多的请求,Lion Cove只能像Zen 5那样,依靠L2缓存来处理大量来自L1缓存的未命中数据。由于L2缓存延迟较高,这可能会让英特尔处于劣势。

在L2缓存之后,二者表现难分高下。有时,英特尔更高的L2缓存命中率会让AMD饱受L3缓存延迟之苦;而有时,工作负载的数据量足够大,英特尔较慢的L3缓存和DRAM访问速度就会拖后腿。
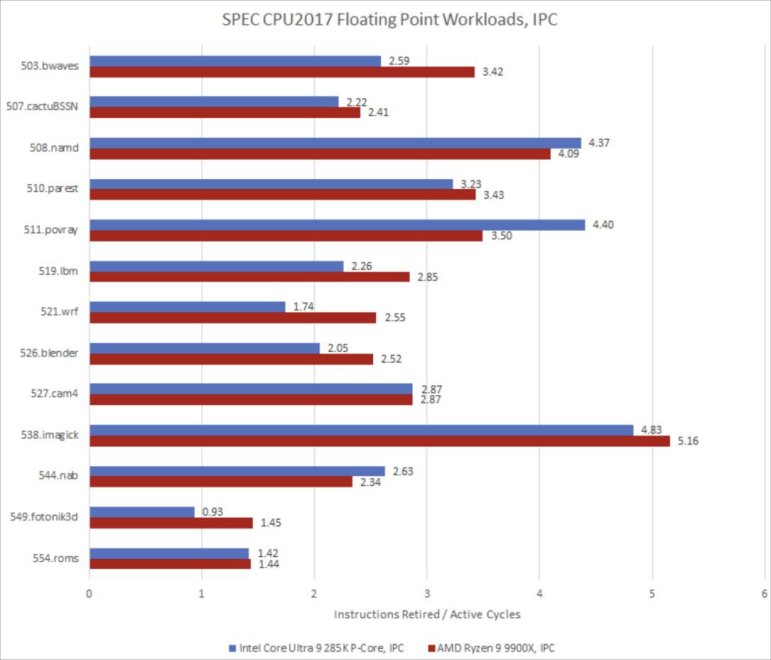
SPEC CPU2017的浮点测试套件也很有意思,因为它包含了一些每时钟周期指令数(IPC)极高的工作负载。英特尔在Lion Cove架构上重新设计了执行端口布局,打造出一组与标量整数端口分开的四个向量/浮点端口。对于浮点运算而言,V0和V1端口可以处理浮点乘法以及融合乘加运算;V2和V3端口则负责处理延迟更低的浮点加法运算。

创建一个良好的端口布局,关键在于确保常用的执行单元能在各个端口间合理分布。如果这点没做好,一两个端口可能会承受过重的负载。在SPEC CPU2017的所有工作负载中,508.namd的每时钟周期指令数(IPC)是最高的,并且大量使用两个浮点乘加(FMA)端口。实际负载甚至可能更高,因为我使用的事件(FP_ARITH_DISPATCHED.Vn)只统计浮点运算,任何SIMD整数运算都可能进一步增加端口使用率。

其他工作负载对端口吞吐量的需求没有那么高,因此执行单元布局也就无需过多担忧。四个端口之间的负载通常也无法很好地平衡。要是能在每个端口都配备浮点加法(FADD)和浮点乘加(FMA)单元,那自然是最理想的。不过浮点执行单元成本高昂,这么做可能只会让少数每时钟周期指令数极高的工作负载获得些许提升。考虑到这一点,Lion Cove的浮点端口布局算是经过深思熟虑的。
libx264视频编码
SPEC CPU2017依赖编译器生成的代码,但很多软件会使用内建函数或汇编代码来充分利用向量指令。我以libx264为例来说明这一点。Lion Cove延续了英特尔在矢量化代码方面表现出色的传统,在核心数量匹配的测试中,它比Zen 5领先4% 。这两款高性能核心都远远领先于Skymont,即便Zen 5的同步多线程(SMT)线程未加载,Skymont也难以跟上节奏。英特尔的能效核(E-Core)产品线向来在处理向量工作负载时表现较弱。虽说每一代能效核都在改进向量执行能力,但面积限制决定了改进的程度。
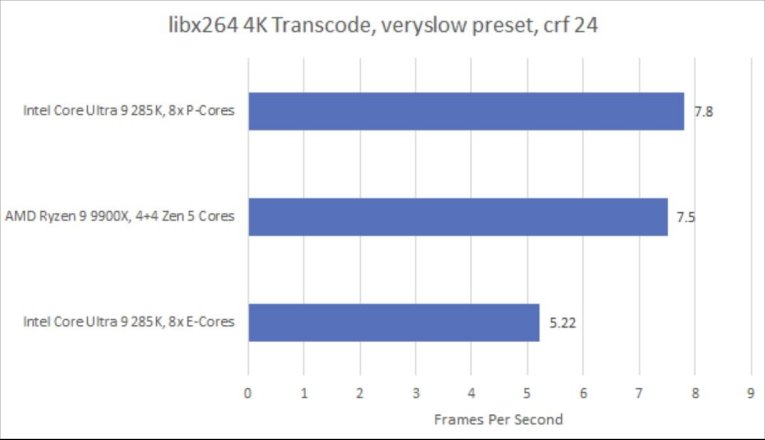
在这项工作负载中,Lion Cove的L1.5缓存缓解了L2缓存的部分压力,这一点值得称赞。不过,Lion Cove和Zen 5都是依靠L2缓存来处理大多数L1未命中的数据。虽然AMD和英特尔的权衡方式有所不同,但如今这两家公司都使用了相对较大的L2缓存,以便让数据更靠近核心。同样,也有不少请求会发往L3缓存和DRAM。
为了测试锐龙9 9900X上的八个核心,不得不将工作负载拆分到该芯片的两个6核簇上。AMD的内存子系统可能需要在这两个簇之间执行缓存到缓存的传输,以维持缓存一致性。不过,性能计数器显示,与常规的L3命中或DRAM访问相比,这种跨CCX(CPU Complex,CPU核心复合体)的流量非常少见。这就是为什么我不会太看重核心到核心延迟测试结果的原因。
7-Zip
7-Zip是一款流行的文件压缩程序。在这里,我正在压缩一个2.67GB的ETL(性能跟踪)文件。7-Zip几乎只使用标量整数指令。Skymont提升了它的相对位置,不过Lion Cove相较于这个针对密度优化的搭档,仍保持着26%的大幅领先优势。虽然不是50%,但这样的差距仍然过大,Skymont还无法跻身高性能行列。
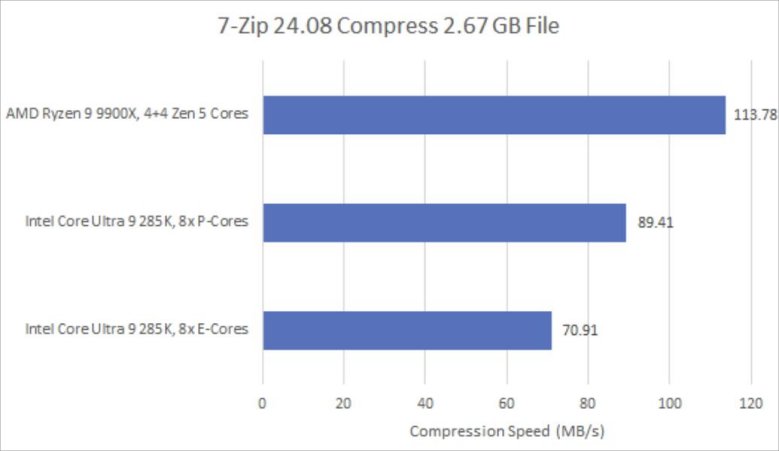
同样,我通过将工作负载拆分到9900X的两个CCD(芯片核心复合体)上来匹配核心数量。Lion Cove似乎在压缩工作负载方面表现欠佳,在SPEC CPU2017的557.xz工作负载测试中,甚至落后于上一代的Raptor Cove。我尝试将7-Zip放在单个CCD上,以便与总缓存容量相近的六核进行对比,但Zen 5依旧能领先大致相同的幅度。
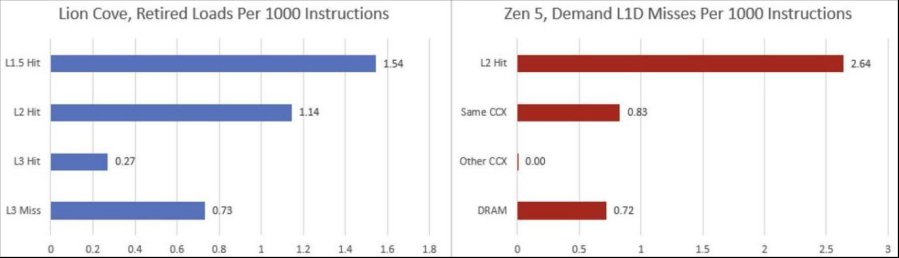
8-Zip内存占用较大。Lion Cove和Zen 5的大容量L2缓存都能很好地处理L1未命中的流量,Lion Cove的L1.5缓存表现也不错。然而,在这两款CPU上,不少未命中L2缓存的访问请求也没能被L3缓存捕获。即便每1000条指令仅有0.7次DRAM访问,也会对性能产生不利影响。一次DRAM访问会让Lion Cove核心耗费超过565个时钟周期,Zen 5核心则需耗费超过484个时钟周期。从这个角度看,Lion Cove、Zen 5,甚至Skymont在这项工作负载下平均每时钟周期指令数(IPC)都能超过1,这让我印象深刻。
结语
Arrow Lake 显示,Lion Cove 大体上能与 AMD 最新的 Zen 5 核心并驾齐驱,在部分工作负载中表现更佳,但在另外一些负载下则会落后。就英特尔而言,这算不上亮眼的成果。我搭建 Zen 5 测试系统时,采用了便捷又低成本的方式,用 AMD 提供的 9900X 替换7950X3D,其余配置维持原样,也就意味着它搭配的是原有的 2 条 32GB DDR5 - 5600 内存模组。乔治(昵称 “Cheese”)搭建的 Core Ultra 9 285K 系统配备的是 2 条 24GB DDR5 - 8000 内存模组。截至 2024 年 12 月 23 日,这套 DDR5 内存售价 150 美元,而速度更快的那套则卖 250 美元。在核心数量匹配的测试里,Lion Cove 使用更昂贵、容量更低的内存,却只获得相近的性能,实在难以让人满意。
由此,人们很容易将英特尔视为一家迷失方向、无法从停滞阶段恢复元气的公司。然而,只着眼于整体,往往会遗漏细节,实际上 Lion Cove 有诸多令人瞩目的细节。英特尔的 8 路解码器能够在 5.7GHz 频率下运行,并且辅以大容量的 64KB 指令缓存。相比之下,AMD 每个线程仅能分配到 4 个解码槽位。Lion Cove 的重命名器处理带有小立即数的加法运算时,几乎可实现零延迟。在后端,L1.5 缓存对于控制 L1 缓存未命中流量的效果出奇得好。为缓解延迟问题,Lion Cove 的重排序容量依旧超过 Zen 5。从 Raptor Cove 到 Lion Cove 的变革幅度极大,几乎流水线的各个环节均得到了改进,乱序执行引擎也完成了重组。
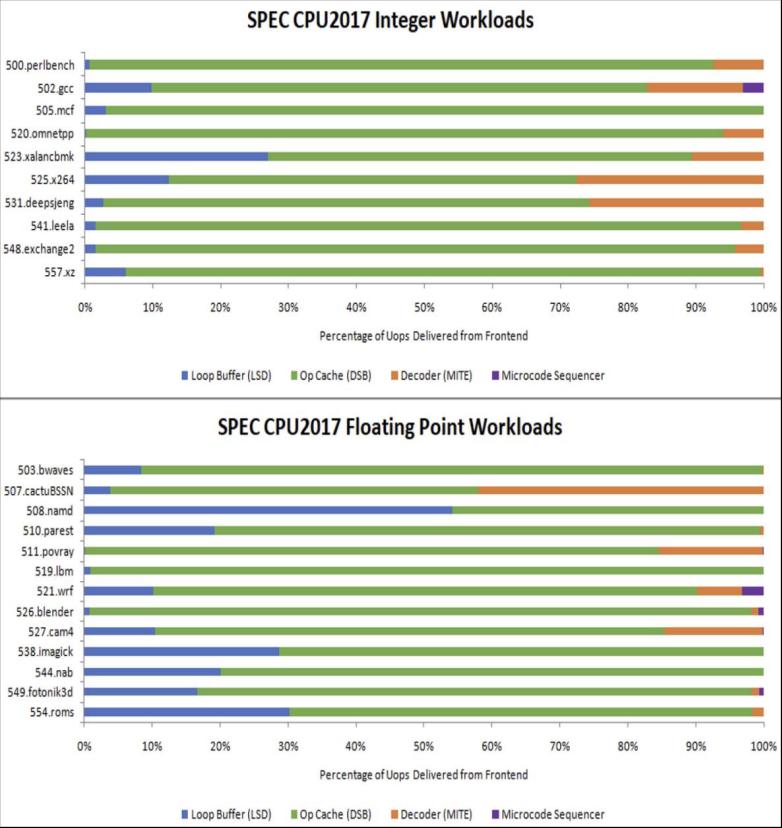
但并非所有这些特性都能转化为性能优势。以8路解码器为例,只有当操作缓存命中率较低,且工作负载的每时钟周期指令数(IPC)足够高,足以突破AMD 4路解码器的极限时,更宽的解码器才会发挥作用。但满足这些条件的工作负载并不多。在AMD和英特尔的最新款核心中,操作缓存命中率通常都很高。507.cactuBSSN最接近让解码器满负荷工作,但即便如此,在Lion Cove上,解码器处理的微操作(uops)也不到交付总量的一半。Zen 5则有所不同,它拥有一个更大且优化更好的操作缓存,这使得解码器处理的微操作不到25%。这些都无关紧要,因为在该项测试中,Lion Cove和Zen 5的平均每时钟周期指令数分别为2.22和2.41。只要有足够大的队列来缓冲指令带宽需求的峰值,4路解码器就能维持这样的吞吐量。 Lion Cove的先进重命名器理应应用更广泛,但在每时钟周期指令数极高的工作负载之外,其效果可能有限。L1.5缓存确实有助于降低L1D未命中的延迟,但这在一定程度上也是为了抵消较高的L2延迟。而较高的L2延迟,是因为L2未命中的代价太大,所以需要更大的L2缓存。这就涉及到Arrow Lake的互连和小芯片设置了,高延迟削弱了Lion Cove的性能潜力。
或许英特尔本可以按部就班,将Lion Cove集成到单片芯片上,复用Raptor Lake的系统代理。这或许能带来短期的成功。但英特尔正试图确保他们拥有一个可扩展的基础,以便基于Arrow Lake继续构建。再看AMD的Infinity Fabric和小芯片架构,它们最终让AMD公司似乎能够随心所欲地组合各类IP模块。当然,在前几代Zen处理器中,这些优势都还不明显。AMD最初的小芯片架构的DRAM延迟也比英特尔的单片芯片更高,而且有好几代产品,AMD的单线程性能都无法超越英特尔。

Arrow Lake和Lion Cove展现出这样一幅画面:英特尔并非停滞不前,而是在拼命努力,让自己重回稳固的根基。与上一代相比,这带来了巨大的变革。这些变革对如今Lion Cove的性能来说并非总是有益,但旨在助力未来设计得更加出色。从某种程度上说,英特尔正试图实现一场类似Zen的转型,只不过相较于2017年之前的AMD,它有着好得多的起点。但愿这一切能让英特尔取得成功。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序