阿里开源Qwen3,昇腾、海光等神速适配
今天凌晨,阿里巴巴开源新一代通义千问模型Qwen3,参数量为DeepSeek-R1的1/3,成本大幅下降。
作为国内首个 “混合推理模型”,Qwen3融合 “快思考” 与 “慢思考”,简单需求低算力秒答,复杂问题多步骤推理,大幅节省算力。它采用MoE架构,总参数量2350亿,但激活仅需220亿,预训练数据量从Qwen2.5的18万亿 token扩展至36万亿 token,新增119种语言及方言支持,涵盖PDF文档解析、STEM领域教材、代码片段等高质量数据。
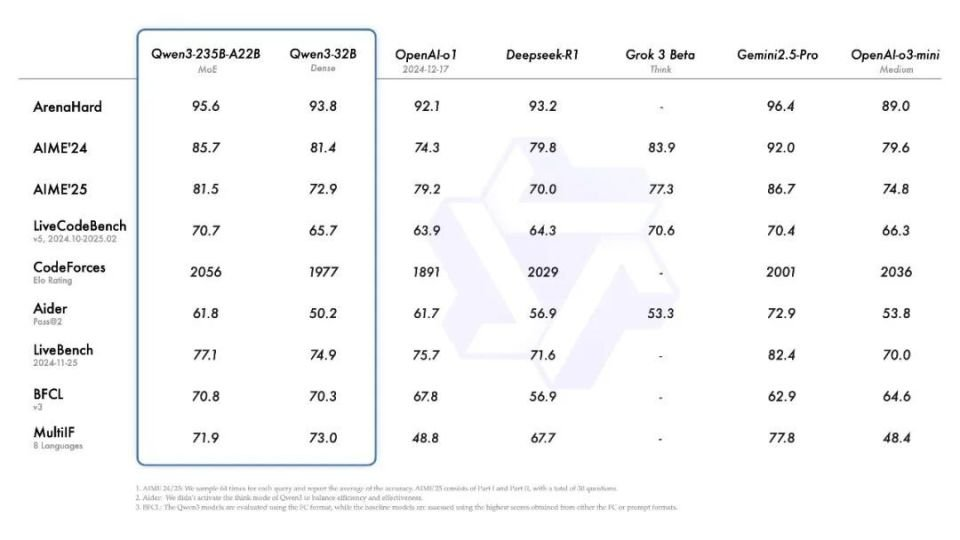
通过Qwen2.5-VL视觉模型辅助提取文档文本,结合Qwen2.5-Math与Qwen2.5-Coder合成数学及代码数据,模型在专业领域的理解能力显著增强。AIME25测评获81.5分刷新开源纪录LiveCodeBench评测超70分优于Grok3,ArenaHard测评95.6分超越OpenAI-o1等。
模型版本丰富,含2款MoE模型与6款密集模型,各尺寸均实现性能最优。4B 适配手机,8B 可流畅运行于电脑和汽车,32B受企业青睐。且所有版本均支持按需设置 “思考预算”,满足不同场景需求。
在智能体领域,Qwen3 在BFCL评测中获70.8分超越顶尖模型,原生支持MCP协议,结合Qwen-Agent框架,降低工具调用门槛与编码复杂度。
在相同计算资源下,Qwen3 模型以更小的规模实现了对更大体量上一代模型的超越,真正做到了“小而强大”。通过 “长思维链冷启动 - 强化学习 - 模式融合 - 通用优化” 四阶段后训练,Qwen3 实现推理能力与响应速度的深度整合。例如,30B 参数的 MoE 模型 Qwen3-30B-A3B 仅激活 3B 参数,即可达到上代 32B 密集模型的性能,部署成本降至同类模型的 1/3,仅需 4 张 H20 显卡即可运行满血版,而性能相近的DeepSeek-R1则需要8到16张H20显卡,显存占用为 DeepSeek-R1 的三分之一。
目前,Qwen3系列模型依旧采用宽松的Apache2.0协议开源,全球开发者、研究机构和企业均可免费在魔搭社区、HuggingFace等平台下载模型并商用,也可以通过阿里云百炼调用Qwen3的API服务。
Qwen3开源之后,吸引了多个行业的头部企业和技术伙伴展开适配与合作。下面,我们就来盘点一点都有谁在连夜适配和调用Qwen3?
昇腾全系列支持Qwen3
在Qwen3模型开源数小时后,华为官方宣布昇腾支持Qwen3全系列模型部署,开发者在MindSpeed和MindIE中开箱即用,实现Qwen3的0Day适配。
此前昇腾MindSpeed和MindIE一直同步支持Qwen系列模型,此次Qwen3系列一经发布开源,即在MindSpeed和MindIE中开箱即用,实现Qwen3的0Day适配。
同时,昇思MindSpore基于对Qwen2.5的支持与兼容主流生态的接口,快速实现Qwen3的0Day支持,并将MindSpore版Qwen3代码上传至开源社区代码仓,面向开发者提供开箱即用的模型。
海光DCU适配Qwen3
在“深算智能”战略引领下,海光DCU迅速完成对全部8款模型的无缝适配+调优,覆盖235B/32B/30B/14B/8B/4B/1.7B/0.6B,实现零报错、零兼容性问题的秒级部署。
基于GPGPU架构的生态优势,与编程开发软件栈DTK的领先特性,Qwen3在海光DCU上展现出卓越的推理性能与稳定性,充分验证海光DCU高通用性、高生态兼容度及自主可控的技术优势,已成为支撑AI大模型训练与推理的关键基础设施。
多家头部芯片公司适配Qwen3
不只是国内厂商在快速适配,国外多家头部芯片公司也在积极适配Qwen3。
据悉,英伟达、高通、联发科、AMD等多家头部芯片厂商已适配Qwen3,在不同硬件平台和软件栈上的推理效率均显著提升,可满足移动终端和数据中心场景的AI推理需求。
通义App全面上线,夸克即将接入
Qwen3开源之后,通义App第一时间上线,夸克也将全线接入Qwen3。
目前,Qwen3-235B-A22B和Qwen3-32B两款模型均已在通义App和通义网页版中的“千问大模型”智能体上线。同时,在通义App与网页版的主对话页面中,用户可以在逻辑推理、编程、翻译等垂类场景下体验到Qwen3的顶级智能能力。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序